Week one at Semaloop

Sam·March 30, 2026
I'm Sam, and I'm a Founding Engineer at Semaloop. I've done a lot of interviewing in the past, and my favourite part of any interview is the five or ten minutes at the end where candidates get to grill you in return. One of the questions I hear a lot in this section is "What's a typical week like?"
At early stage startups (and actually far beyond that too) there's rarely a 'typical' week, but the underlying question is good: what is it you actually do? Given that I've just finished my first week at Semaloop, and the fact that we're hiring, I thought it'd be interesting to write about why I joined Semaloop, and what my first week has been like.
Why Semaloop?
There were a bunch of reasons I joined. There's the people: I've had the pleasure of working with half of the company (Charlie and Dani) before in my previous job, and when I hung out with Rory and saw what he'd built so far, I quickly saw how switched on he was, and how much cool and interesting stuff he'd built. Then there's the product: there's clear traction with our early customers, and so many options for what we do next. I'm excited to pick apart what the next most important things are with our users.
However, 'the people' and 'the product' are table stakes things for me, and I've been lucky enough to have a string of jobs where I've worked with great people on products that customers love. So, why Semaloop specifically?
For me, a lot of it is about being in at the deep end of something early stage, and being a technical generalist with an incredibly clear goal. Let me show you what I mean, by walking you through week one.
Getting started
Monday was a classic. Unbox a shiny new MacBook Pro (M4 Max to be specific, these things matter), and speed-run getting my laptop set up just how I like it: something I now have down to a fine art. I'd already been sent the onboarding document from Notion the week before, so I knew what was in store, and set to running through the ticklist of accounts to set up and things to download — although macOS Mobile Device Management meant I already had all the apps I'd need.
I already knew there was a curve-ball coming later in the week: on Wednesday, our CTO Rory was going to be jetting off to Hong Kong for a wedding, leaving me as a solo engineer (sorry Charlie, I know you have a Computer Science degree). We've got a decent chunk of documentation, but this meant we spent as much time together as possible talking through architecture, tools, database schemas, and much more. Rory fielded about 1,000 questions from me.
The first day was mostly about getting my local environment set up. As engineer number two, that meant making sure our setup documentation still made sense, and automating the setup of a few of the tools we use for local development. When you're controlling iPhones and running tests, there's quite a number of those.
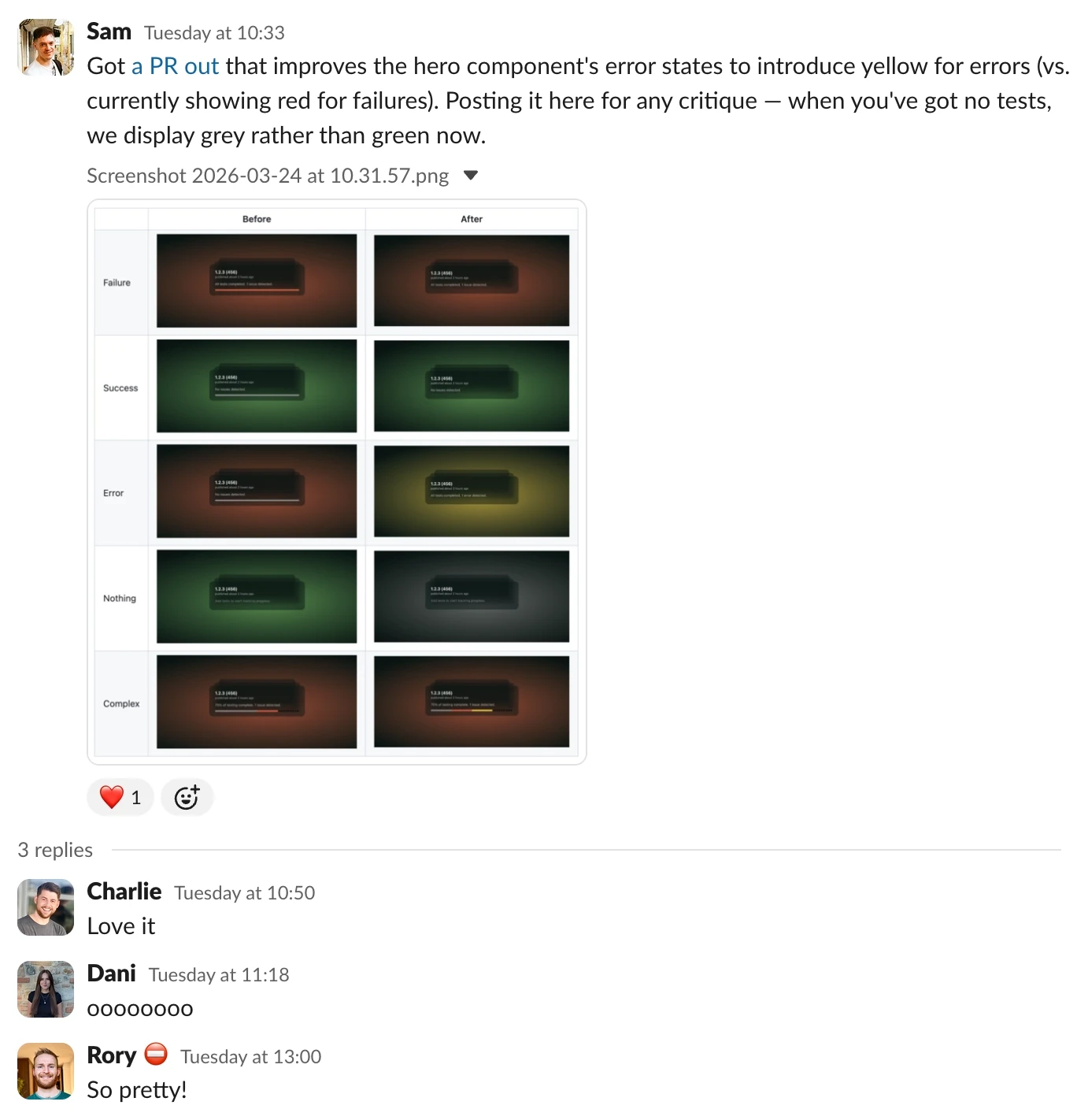
I shipped my first change on Tuesday: ensuring that the colours we show you on your 'build' page more clearly reflect what happened with your tests. We previously didn't differentiate between a test that failed (i.e. an expectation wasn't met) and a test that errored (e.g. because a device rebooted), and that could cause a bit of confusion. After my change, you now see a lovely shade of yellow for errored tests. This was a nice gentle introduction to our front-end (React) and backend (also Typescript), as well as our CI pipelines.
Tuesday was rounded off with a little celebration dinner with another Founding Engineer who's joining us soon, and featured a small wave of Aperol Spritz-based disappointment. This was, however, offset by excellent pasta.

Ramping up
Wednesday was when I started to dive into my first project: the ability to run tests against simulated devices, as well as real devices. That'll mean we'll be able to run more tests in parallel, and (hopefully) faster. Stay tuned. This involved me doing some research and writing up a product spec that describes what we're building, as well as a tech scope that outlines the engineering work that's involved.
This project involves working on our workers. This layer co-ordinates which devices run which tests, and supervises those tests as they run. It was a nice step up in complexity. The workers are written in Python, and Rory and I did a once over of the codebase so I could get the lay of the land. I got a good kick out of seeing the iPhone on my desk light up and run its first test.

My first incident
Then there was Thursday… It was just Dani and I in the office, and we turned up to news that the building's toilets were all out of service. We soldiered through until lunch, went to get food, and then came back to an office with a mildly-flooded ground floor and no power.
I'll spare you the details, but given some of our devices are hosted in the office (which gives us easy access), this meant we were operating at reduced capacity and also left Dani and I temporarily deskless. After a status page update, a couple of phone calls and a flurry of emails, we'd hatched a plan and sorted out somewhere else to work. Earlier in the week I'd taken some metrics we have in Logfire and started pushing them into Grafana. This incident gave a near-instant payoff on that work, and meant we could see slightly more granular detail about which devices are offline, and when.
Friday, thankfully, was relatively pedestrian: I got my head down and cracked on with project work.
All of the above is exactly why I'm here: and I've not even covered things like our employer branding workshop, working with designers on an overhaul of our website, and talking to our customers. Week one had all of the kinds of problems that I love dealing with, along with all the trust and support I need to do a great job of solving them.
I'm writing this partly as a reflection, but mostly so other engineers out there can read this and think "Yeah, I want my first week to be like that too". If you're thinking that, you should come and join us. We're hiring for our final Founding Engineer, and I'd love to chat to you about it.
Sam·March 30, 2026